Building Codestyle: Teaching Claude Code Your Team's Conventions
The Problem
My team and I have been going harder on agentic coding with Claude Code. It's fast, capable, and integrates well with our workflow.
But there's a recurring frustration: during code reviews, I keep leaving comments about patterns I've already given feedback on before. The same antipatterns show up because the agent doesn't know our conventions.
The obvious fix is to put these conventions in a CLAUDE.md so the agent avoids the antipatterns from the start. But writing a comprehensive CLAUDE.md by hand is daunting. You'd have to recall every convention, every preference, every pattern your team has evolved over months or years. Most of this knowledge is implicit—nobody wrote it down because "everyone just knows."
The Insight
It doesn't need to be done by hand. Your repository's review history already contains all the relevant information. Every comment a reviewer left, every change made after feedback—that's your team's conventions, encoded in pull request history.
Don't learn from the codebase. Learn from the code reviews.
You shouldn't try to learn coding patterns from the codebase itself. A codebase that's been worked on for years by many people contains a lot of code that doesn't comply with the patterns you want to promote today. Even code shipped by the current team is too low-signal. Generating guidelines from all that code produces guidelines that are too generic and just burn tokens for no good reason.
The key is to focus on the changes that were made as a result of code reviews. That's the high-signal data—the moments where someone said "actually, we do it this way."
Enter Codestyle
Codestyle retrieves all PRs merged into your main branch from the last year and analyzes two things: the comments made by reviewers, and the code changes that happened after the first review.
This is high-signal data because it focuses on things that weren't right the first time—the delta between "submitted for review" and "merged."
From this analysis, codestyle generates a CLAUDE.md. And it works—I don't have to leave the same review comments anymore.
The Review Skill
But sometimes conventions still slip through the cracks. That's why codestyle also generates a review.md—a skill file containing the same information about patterns and antipatterns, but formatted as a review checklist.
Before submitting a PR—in CI, as a commit hook, or just manually—you can run the review skill to catch mistakes that slipped through.
Agents, just like humans, make mistakes when following complicated guidelines. But both can correct their own work when they run it against a checklist.
Designing the User Experience
With the core idea validated, the next challenge was making the tool pleasant to use. Every point of friction is a chance for the user to give up.
What I Didn't Do: Flags for Everything
The obvious approach for a CLI is flags:
codestyle --github-token ghp_xxx --api-key sk-ant-xxx --owner myorg --repo myrepoIt front-loads all the complexity. Users give up before they even see what the tool does.
What I Didn't Do: Config File First
Another approach: require users to create a config file before running:
# ~/.codestyle.yaml
github_token: ghp_xxx
anthropic_api_key: sk-ant-xxxEven worse. Now users have to create a file, in the right location, with the right format, before they can try the tool. The activation energy is too high.
What I Did: Guided Interactive Flow
Instead, running codestyle generate walks you through everything step by step:
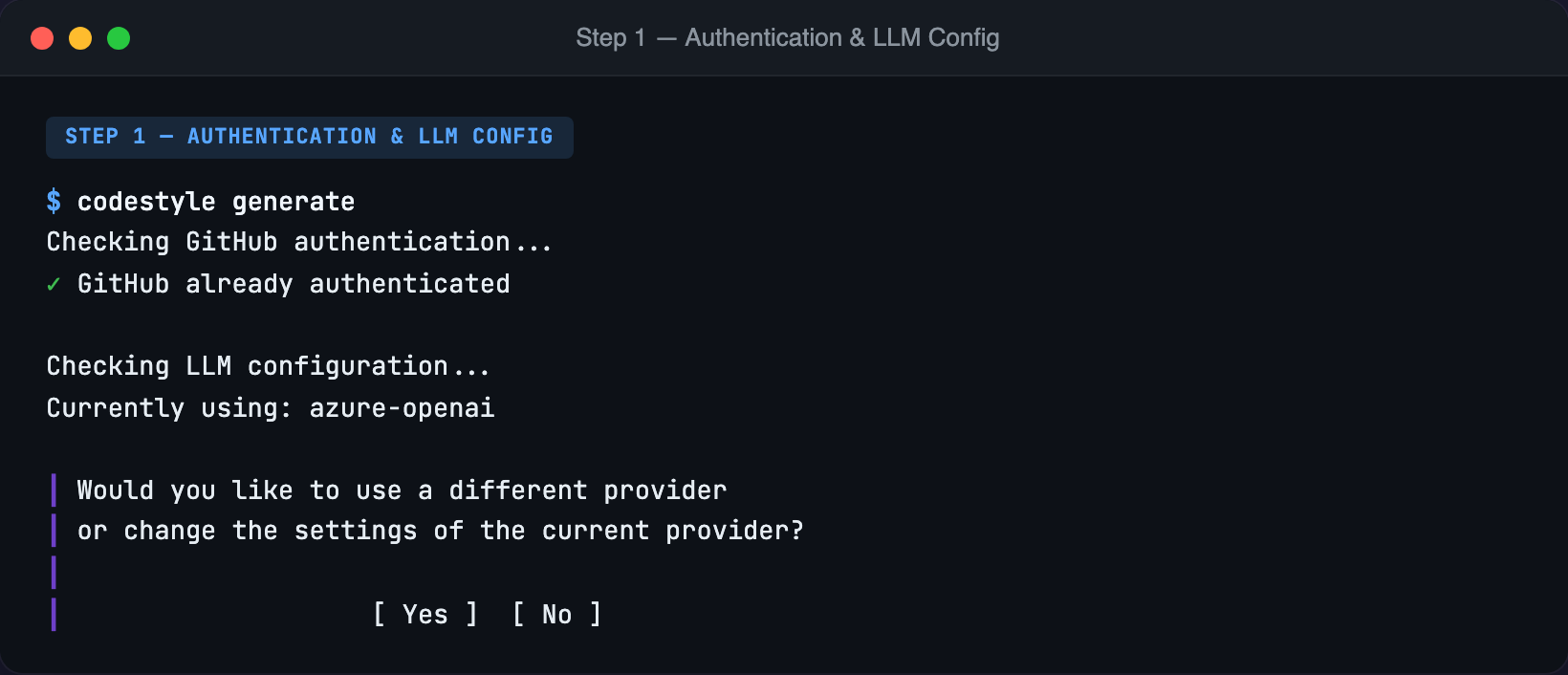
The tool checks your GitHub authentication, shows your current API key status, and only prompts if something needs to change. First-time users see the full setup; returning users skip straight through.
Zero prerequisite knowledge. The browser opens automatically with the OAuth flow. Progressive disclosure. Each step appears only when needed. No memorization. Users pick from lists instead of typing names. Credentials stored automatically after first run.
GitHub OAuth Device Flow
For GitHub authentication, I chose the Device Flow—the same flow as gh auth login. Open browser, enter code, done.
Even the Device Flow had a subtle UX problem in my initial implementation. The browser opened before the user saw the authorization code. They'd land on GitHub's page and wonder: "What code?"
The fix: show the code first, offer to copy it to the clipboard with a single keypress, then open the browser. When users land on GitHub's page, they just paste. A small detail, but the difference between feeling polished and feeling like a prototype.
Repository Selection
Once authenticated, the tool fetches your repositories and presents them as a searchable list:
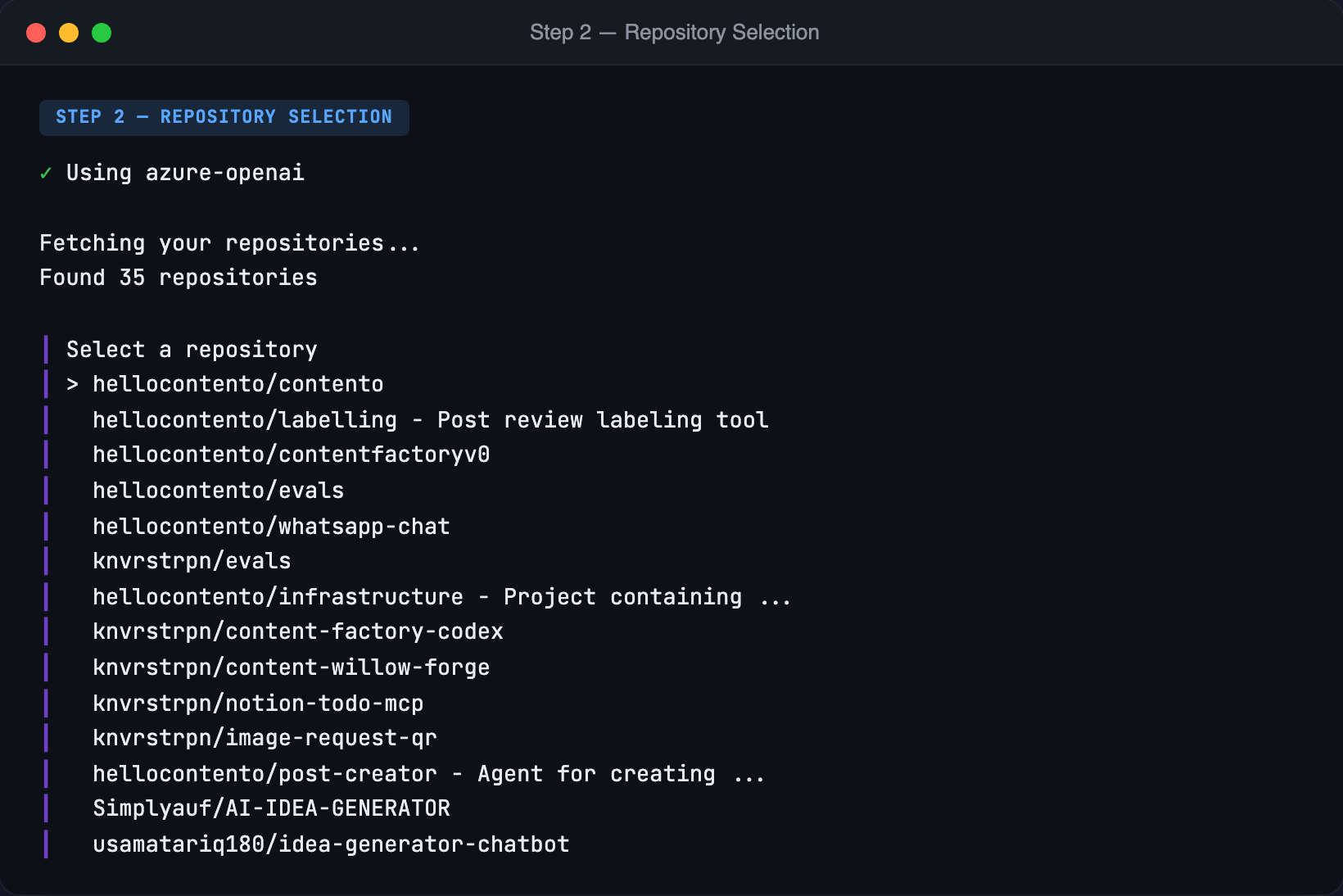
No guessing, no typos, no "which org was that under again?"
One Command Does Everything
I originally planned separate commands: extract for guidelines and checklist for the review checklist. But this created confusion: what's the difference? Which one should I run first?
One command (generate) that produces everything. Guidelines and checklist together, because that's how they'll be used.
Friction Compounds
Every point of friction compounds. If step 1 has 90% completion rate and step 2 has 90%, you've already lost 19% of users before step 3.
A five-step flow with 90% completion at each step retains only 59% of users.
This is why I obsess over these details:
- Don't make users leave the terminal. Show them everything they need.
- Don't make users remember things. Copy to clipboard. Pre-fill defaults.
- Don't make users know the internals. Provide commands for common operations.
- Default to yes. One keypress to continue.
The Analysis Pipeline
With the CLI experience polished, let's look under the hood. The core challenge: how do you extract meaningful patterns from dozens of PRs without overwhelming the LLM's context window?
Two-Stage Analysis
The naive approach—dump all PR data into one massive prompt—fails. Even with 200K token windows, 50 PRs with full diffs easily exceed the limit, and the LLM struggles to find patterns buried in noise.
Instead, codestyle uses a two-stage pipeline:
Stage 1: Per-PR Analysis. Each PR is analyzed independently. The LLM receives the review comments, the code evolution, and the diff context. It extracts guidelines: style preferences, architectural patterns, best practices. PRs with no meaningful feedback get skipped.
Stage 2: Aggregation. All per-PR guidelines feed into a second prompt that consolidates duplicates ("use early returns" appearing in 12 PRs becomes one guideline), organizes by category, resolves conflicts, and generates the final output.
This scales to any number of PRs. Analyze 500? Run stage 1 on each, aggregate the results.
Adaptive Rate Limiting
One per PR, potentially hundreds of LLM calls. Sequentially? Far too slow. All at once? Instant rate limits.
Fixed batch sizes (10 concurrent calls per batch) are brittle—after the initial burst you're leaving throughput on the table, and rate limits aren't enforced consistently.
Instead, I implemented an adaptive rate limiter:
- Launch calls at fixed intervals, starting from an interval derived from the known rate limits. Any starting value works—the system adapts.
- On success, speed up by shrinking the interval. I've reached speeds that are a multiple of the official rate limits.
- On rate limit: back off. Pause, wait the indicated duration, increase the interval, retry, continue.
What would take 5+ minutes sequentially completes in under a minute.
One might argue this oscillates—hit limits, slow down, speed up, repeat. In practice it doesn't, because the adaptation is slow relative to the number of calls. If it did, you could add memory: the system remembers where it was last rate-limited and approaches that threshold more cautiously.
Here's what it looks like in practice:
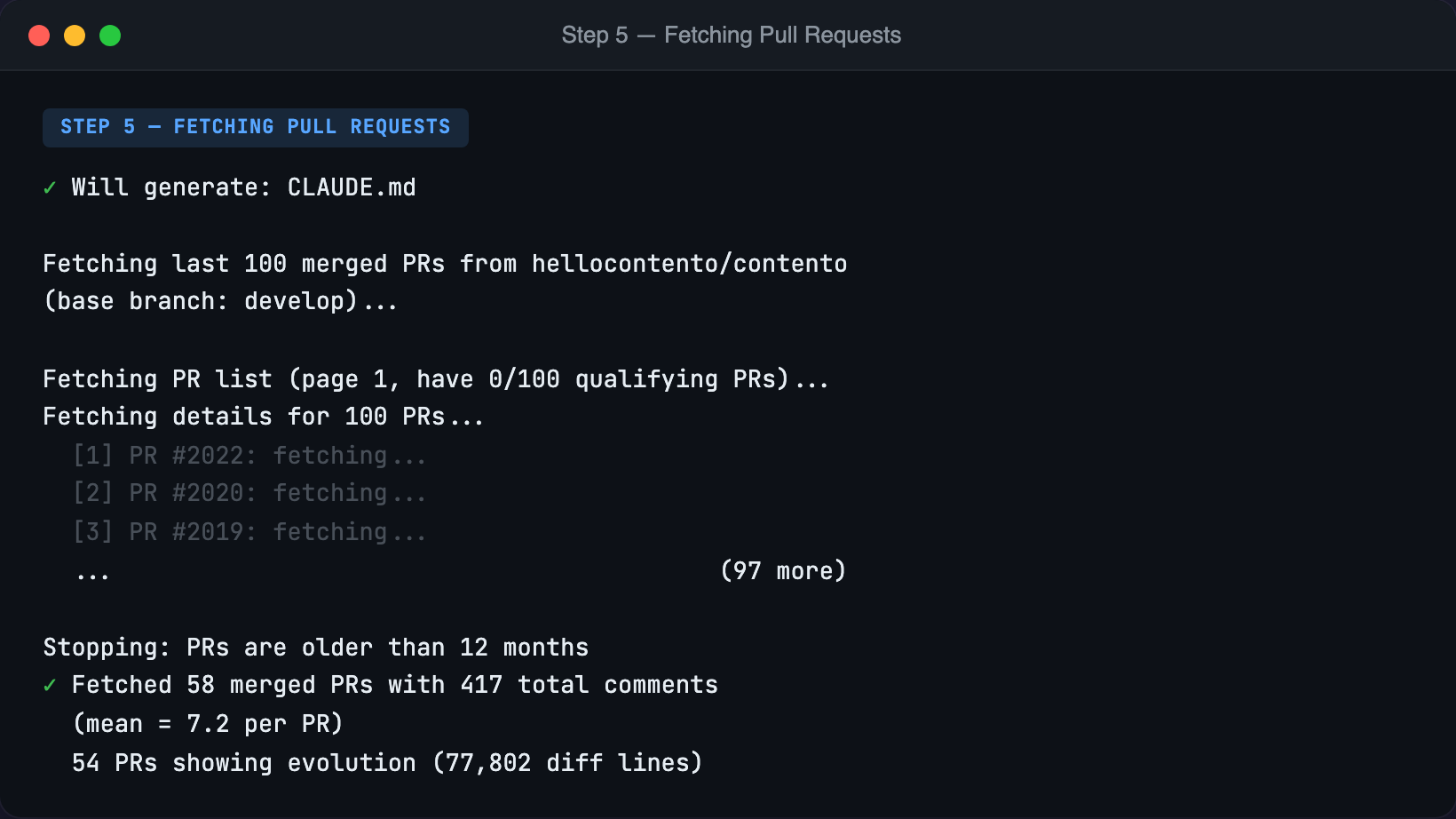
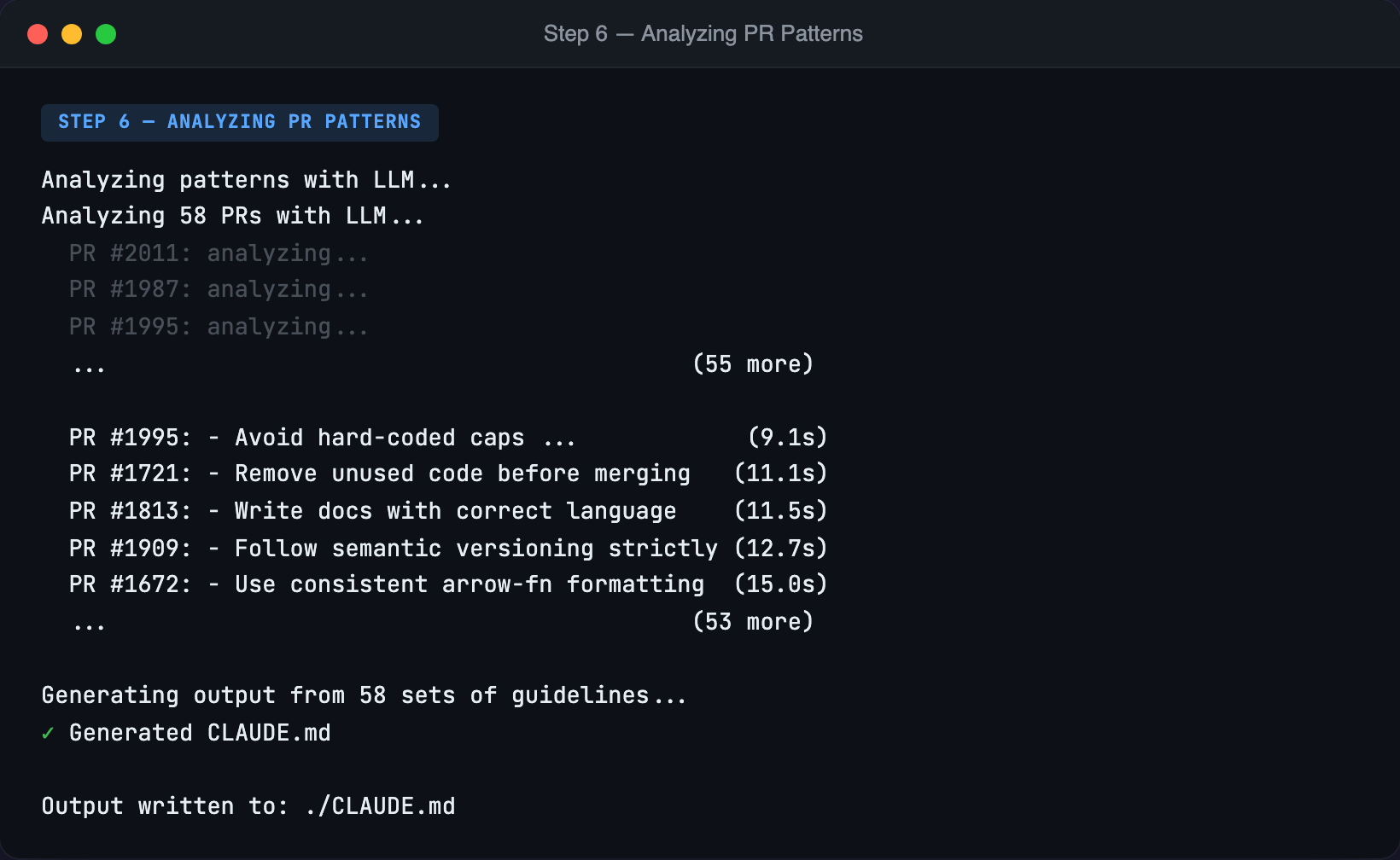
Capturing PR Evolution
Most PR analysis tools miss something subtle: the difference between what was proposed and what was merged.
The interesting signal is the delta introduced by the review process—what changed between "ready for review" and "merged." This encodes what the team corrected, improved, or insisted on.
GitHub's review API tells us which commit each review was submitted against. For each PR, we compute two diffs:
- Proposed changes: first reviewed commit vs base (what reviewers initially saw)
- Merged changes: last commit vs base (what was ultimately merged)
When these differ, the review process changed something. The LLM sees both diffs and can infer: "The initial proposal used nested if-statements, but the merged version uses early returns."
This beats using the first commit in the branch, which might be work-in-progress code. The first review marks when the author considered it review-worthy.
Principles, Not Rules
A key insight from early iterations: the extracted guidelines were too specific. File paths, function names, technology-specific patterns. A guideline like "Put string utilities in frontend/src/utils/string.ts" isn't useful in a different codebase.
The solution: instruct the LLM to extract principles, not rules. That example becomes "Organize utility functions by concern in dedicated utility modules." The principle transfers; the specific path doesn't.
The Output
The tool generates three files:
CLAUDE.md — A focused list of 15-25 principles using imperative statements ("Prefer", "Use", "Always") that Claude Code follows when generating code.
review.md — A review checklist with two sections: a synthesized style checklist, and an "Implicit Decisions" section that surfaces consequential choices—data structure selection, error handling strategy, where new code lives. These aren't problems; they're decisions worth explicit acknowledgment before merge.
commit.md — A quick pre-commit self-check focused on the most common mistakes caught in PR reviews.
Data Quality
Before analyzing, the tool computes statistics: total review comments, mean comments per PR, PRs with code evolution.
Not enough comments? Reviewers might be rubber-stamping. No code evolution? You're not capturing implicit feedback. Too few PRs? 50 is a good starting point; 200+ gives high confidence.
Automated Releases with GoReleaser
Building a Go binary is easy. Distributing it across platforms and package managers is where it gets tedious.
GoReleaser automates all of this. On every Git tag, a GitHub Actions workflow cross-compiles for all targets, creates archives with checksums, publishes to GitHub Releases, and updates Homebrew and Scoop automatically.
The setup requires two package manager repositories:
gh repo create koenverstrepen/homebrew-tap --public
gh repo create koenverstrepen/scoop-bucket --publicAnd a release workflow:
name: Release
on:
push:
tags:
- 'v*'
permissions:
contents: write
jobs:
release:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
with:
fetch-depth: 0
- uses: actions/setup-go@v5
with:
go-version: '1.23'
- uses: goreleaser/goreleaser-action@v6
with:
version: latest
args: release --clean
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
HOMEBREW_TAP_GITHUB_TOKEN: ${{ secrets.HOMEBREW_TAP_GITHUB_TOKEN }}
SCOOP_BUCKET_GITHUB_TOKEN: ${{ secrets.SCOOP_BUCKET_GITHUB_TOKEN }}After setup: git tag v0.1.0 && git push origin v0.1.0. Within 3 minutes, binaries appear on GitHub Releases, Homebrew, and Scoop. Tag, push, done.
Building This With Claude Code
I built this entire project using Claude Code (Opus 4.5). This is my first Go project, but that didn't really matter. I can read code, and that includes Go. When I didn't understand syntax or patterns, I just asked.
Claude Code is excellent at scaffolding. It generated the initial structure, set up Cobra for CLI commands, wired up the GitHub OAuth flow, created the Anthropic API client. The code worked. The architecture was reasonable.
Most of my review time focused on two things. Simplicity: the initial implementation had redundant config structs that I flattened. UX decisions: the original code skipped configuration if a key was already set. I changed it to validate the key and prompt for a new one if needed.
Two Futures
This experience made me think about where we're headed.
In one future, AI gets good enough that engineers never need to read code. You describe what you want, the AI builds it, and you interact only at the product level.
In another, AI is powerful but imperfect. The hardest bugs still require a human to dig into the code. In that world, code quality matters more, not less.
I don't know which future we're heading toward. But I suspect we're not yet in the first one. So for now, I'll keep reviewing the code and caring about variable names.
The Vibe-Coding Experiment
That was the plan, at least. But as the project progressed, something shifted.
The Discipline Erodes
I started out diligently reviewing every line Claude wrote. It was also a way to learn Go. I'd read each function, question the patterns, look up unfamiliar syntax.
But the discipline became harder to maintain.
Speed is addictive. The friction between "I want this feature" and "this feature exists" has collapsed. Stopping to carefully review feels like putting the brakes on a sports car.
Opus 4.5 is just very good. My reviews caught stylistic issues—variable names, function organization—but rarely bugs. After a while, you start wondering if the review is worth the time.
The stakes felt low. Side project. Not production code. If there's a bug, I'll find it when I use the tool.
Readability matters less when the LLM explains the code. If I can ask Claude to walk me through any function, does it matter as much if the code is "clean"?
So I started vibe-coding. Accept the generated code, test the behavior, iterate on the product rather than the implementation.
What I Learned
The experiment clarified my thinking. I'm not ready to abandon careful code review for production code. But I did learn that we need to change how we do it.
The bottleneck isn't writing code anymore; it's reviewing it.
The traditional model—human reviews every line—doesn't scale when AI generates code at this velocity. We need to shift effort from reviewing individual PRs to building systems that make reviews unnecessary or automated.
A New Approach for Production Code
1. Invest heavily in the agentic environment. Get most things right from the start.
- A comprehensive CLAUDE.md that encodes team conventions. Review becomes confirmation, not correction.
- A /review skill that checks code against the same guidelines.
- A /commit skill that performs lightweight review before committing.
- A "highlight implicit decisions" step that surfaces consequential choices before merge.
- CI integration that runs the review skill automatically on every PR.
2. Shift human effort from reviewing code to tuning the system.
Instead of linear effort (review every PR), you get multiplicative returns (better guidelines improve every PR forever).
This is exactly why I built codestyle. The tool bootstraps the agentic environment from your existing review culture—instead of writing guidelines from scratch, you extract them from what your team already does.
3. Build "LLM as judge" evals. Create evaluations where an LLM judges code against your team's conventions. Run evals before and after guideline changes. Track whether the changes actually help.
4. Rethink testing. Checking that tests pass is trivial. Checking that tests are implemented correctly is harder. Checking that tests cover the right things is hardest. Coverage metrics tell you what's executed, not what's actually verified.
Two Modes of Operation
For now, I've landed on a dual approach:
Side projects: push to the frontier, test the limits, experiment with minimal review, learn what breaks.
Production code: stay conservative, maintain human review, gradually introduce practices battle-tested in side projects.
The side projects are the R&D lab. Production is where proven practices get deployed.
This isn't a permanent split. As the tooling matures—as CLAUDE.md becomes comprehensive, as review skills become reliable, as CI integration becomes seamless—the gap will close. Eventually, what feels like "vibe-coding" today might just be how we work.
But we're not there yet.